





The latest results of FrontierMath, a reference test for generative AI on advanced mathematics problems, show that the O3 model of Openai was worse than Optaai initially. While the new OpenAi models now surpass O3, the gap highlights the need to examine the benchmarks of AI.
Epoch AI, the research institute that created and administered the test, published its latest results on April 18.
OPENAI claimed 25% test completion in December
Last year, the FrontierMath score for Openai O3 was part of the almost overwhelming number of announcements and promotions published as part of the OpenAi 12 -day holiday event. The company affirmed that Optai O3, then its most powerful reasoning model, had solved more than 25% of the problems on Frontitierart. In comparison, Most rivals models have obtained around 2%According to Techcrunch.
See: For Earth Day, Organizations could take into account the power of the generator in their sustainability efforts.
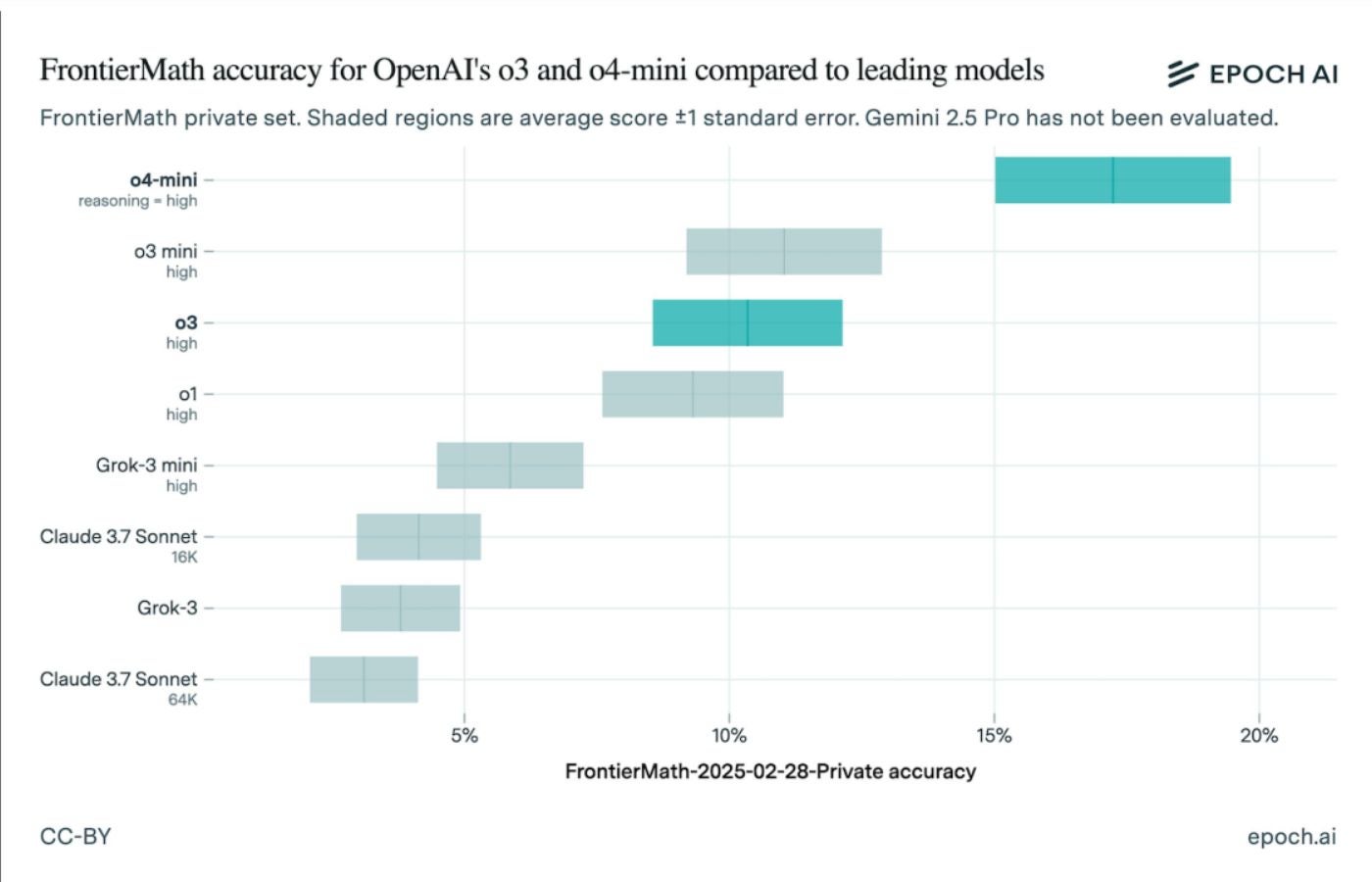
On April 18, Epoch AI was published Test results showing Openai O3 scored closer to 10%. So why is there such a big difference? The model and the test could have been different in December. The version of Openai O3 which had been submitted for comparative analysis last year was a preliminary version. Frontitiermath himself has changed since December, with a different number of mathematical problems. It is not necessarily a reminder of not trusting references; Instead, don’t forget to dig into the version numbers.
OPENAI O4 and O3 MINI MIGANIE TRAIN ON THE NEW RESULTS FRIFFORATIONS
The updated results show Openai O4 with the best reasoning, marking between 15% and 19%. It was followed by Openai O3 Mini, with O3 in third. Other rankings include:
- OPENAI O1
- Grok-3 Mini
- Claude 3.7 SONNET (16K)
- Grok-3
- Claude 3.7 SONNET (64K)
Although Epoch Ai independently administers the test, Openai initially commissioned Frontitierarhath and has its content.
Critics of the AI of comparative analysis
Benchmarks are a common way to compare generative AI models, but criticisms say that the results can be influenced by test design or lack of transparency. A July 2024 study raised concerns that the overestimated references on the accuracy of close tasks and suffer from non -standradic evaluation practices.



