Book released – Six Colors")



Robert Triggs / Android Authority
Cloud AI peut être impressionnant, mais j’aspire à la sécurité supplémentaire que le traitement local ne fournit que le traitement local, en particulier à la lumière des données des utilisateurs de profondeur à la Chine. Le remplacement de Copilot par Deepseek sur mon ordinateur portable hier m’a fait me demander si je pouvais également exécuter de grands modèles de langue hors ligne sur mon smartphone. Après tout, les téléphones phares d’aujourd’hui prétendent être très puissants, ont des piscines de RAM et ont des accélérateurs d’IA dédiés que seuls les PC les plus modernes ou les GPU coûteux peuvent mieux. Certes, cela peut être fait.
Eh bien, il s’avère que vous pouvez exécuter une version condensée de Deepseek (et de nombreux autres modèles de langage large) localement sur votre téléphone sans être attaché à une connexion Internet. Bien que les réponses ne soient pas aussi rapides ou précises que celles du modèle de nuage de taille normale, les téléphones que j’ai testés peuvent produire des réponses à un rythme de lecture rapide, ce qui les rend très utilisables. Surtout, les modèles plus petits sont encore bons pour aider à la résolution de problèmes, expliquer des sujets complexes et même produire du code de travail, tout comme son plus grand frère.
Êtes-vous intéressé par le modèle d’IA de Deepseek?
4803 votes
Je suis très impressionné par les résultats, étant donné qu’il fonctionne sur quelque chose qui tient dans ma poche. Je ne peux pas recommander que vous vous précipitez tous pour me copier, mais ceux qui sont vraiment intéressés par le paysage en constante évolution de l’IA devraient probablement essayer de gérer des modèles locaux pour eux-mêmes.
Robert Triggs / Android Authority
L’installation d’un LLM hors ligne sur votre téléphone peut être une douleur, et l’expérience n’est pas aussi transparente que l’utilisation de Gémeaux de Google. Mon temps passé à creuser et à bricoler a également révélé que les smartphones ne sont pas les environnements les plus adaptés aux débutants pour expérimenter ou développer de nouveaux outils d’IA. Cela devra changer si nous allons avoir un marché concurrentiel pour les applications d’IA convaincantes, permettant aux utilisateurs de se libérer des chaînes OEM d’aujourd’hui.
Les modèles locaux fonctionnent étonnamment bien sur Android, mais les installer n’est pas pour les timides.
Étonnamment, la performance n’était pas vraiment le problème ici; Les smartphones d’élite Snapdragon 8 de pointe, j’ai testés, les modèles de paramètres de sept et huit milliards de paramètres de taille modéré de taille modéré sur leur processeur, avec une vitesse de sortie de 11 jetons par seconde – un peu plus rapide que la plupart des gens ne peuvent lire. Vous pouvez même exécuter le paramètre de 14 milliards de PHI-4 si vous avez suffisamment de RAM, bien que la sortie tombe à six jetons encore passables par seconde. Cependant, Running LLMS est le plus difficile que j’ai poussé des processeurs de smartphones modernes en dehors de l’analyse comparative, et cela se traduit par des combinés assez chauds.
Impressionnant, même le vieillissement Pixel 7 Pro peut exécuter trois milliards de modèles de paramètres plus petits, comme Meta’s LLAMA3.2, à cinq jetons passables par seconde, mais tenter la plus grande profondeur pousse vraiment la limite de ce que les téléphones plus anciens peuvent faire. Malheureusement, il n’y a actuellement aucune accélération NPU ou GPU disponible pour tout smartphone en utilisant les méthodes que j’ai essayées, ce qui donnerait aux téléphones plus anciens une véritable chance dans le bras. En tant que tels, les modèles plus grands sont un non-go absolu, même sur les puces les plus puissantes d’Android.
Sans accès Internet ou fonctions assistantes, peu trouveront les LLM locaux très utiles.
Même avec des combinés modernes puissants, je pense que la grande majorité des gens trouveront les cas d’utilisation pour exécuter un LLM sur leur téléphone très limité. Des modèles impressionnants comme Deepseek, Llama et PHI sont de grands assistants pour travailler sur des projets PC à grand écran, mais vous aurez du mal à utiliser leurs capacités sur un minuscule smartphone. Actuellement, sous forme de téléphone, ils ne peuvent pas accéder à Internet ou interagir avec des fonctions externes comme Google Assistant Routines, et c’est un cauchemar de les transmettre de documents pour résumer via la ligne de commande. Il y a une raison pour laquelle les marques de téléphone incorporent des outils d’IA dans des applications comme la galerie: cibler des cas d’utilisation plus spécifiques est le meilleur moyen pour la plupart des gens d’interagir avec des modèles de différents types.
Ainsi, bien qu’il soit très prometteur que les smartphones puissent exécuter certains des meilleurs LLM compacts, il y a un long chemin à parcourir avant que l’écosystème ne soit sur le point de soutenir le choix des consommateurs chez les assistants. Comme vous le verrez ci-dessous, les smartphones ne sont pas au centre de la formation ou de l’exécution des derniers modèles, sans parler de l’optimisation de la large gamme de capacités d’accélération matérielle que la plate-forme a à offrir. Cela dit, j’aimerais voir plus d’investissement dans les développeurs ici, car il y a clairement la promesse.
Si vous souhaitez toujours essayer d’exécuter Deepseek ou plusieurs des autres modèles de grande langue populaires sur la sécurité de votre propre smartphone, j’ai détaillé deux options pour vous aider à démarrer.
Comment installer Deepseek sur votre téléphone (la manière facile)
Robert Triggs / Android Authority
Si vous voulez une solution super facile pour discuter avec une IA locale sur votre combiné Android ou iOS, vous devriez essayer le Application PocketPal AI. Les propriétaires d’iPhone peuvent également essayer Privatellm. Vous aurez toujours besoin d’un téléphone avec un processeur décent et un pool de RAM rapide; 12 Go est acceptable dans mes tests pour exécuter des modèles 7b / 8b condensés, mais 16 Go est meilleur et essentiel si vous voulez essayer de vous attaquer 14B.
Grâce à l’application, vous pouvez accéder à un large éventail de modèles via le portail populaire HuggingFace, qui contient Deepseek, Llama, PHI et bien d’autres. En fait, le gigantesque portefeuille de HuggingFace est un peu un obstacle pour les non-initiés, et la fonctionnalité de recherche dans PocketPal IA est limitée. Les modèles ne sont pas particulièrement bien étiquetés dans la petite interface utilisateur, il est donc difficile de choisir l’officiel ou optimal pour votre appareil, en dehors d’éviter ceux qui affichent un avertissement de mémoire. Heureusement, vous pouvez importer manuellement des modèles que vous avez téléchargés vous-même, ce qui facilite le processus.
Vous voulez exécuter une IA locale sur votre téléphone? PocketPal AI est un moyen super facile de faire exactement cela.
Malheureusement, j’ai connu quelques bogues avec PocketPal IA, allant des téléchargements ratés aux chats qui ne répondent pas et aux accidents de l’application complets. Fondamentalement, ne naviguez jamais loin de l’application. Un certain nombre de réponses ont également coupé prématurément en raison de la petite taille de fenêtre par défaut (un gros problème pour le Verbose Deepseek), donc bien qu’il soit convivial pour commencer, vous devrez probablement approfondir les paramètres plus complexes. Je ne pouvais pas non plus trouver de moyen de supprimer les chats.
Heureusement, les performances sont vraiment solides et il déchargera automatiquement le modèle pour réduire la RAM lorsqu’il n’est pas utilisé. C’est de loin le moyen la plus facile d’exécuter Deepseek et d’autres modèles populaires hors ligne, mais il y a aussi une autre façon.
… Et à la dure
Robert Triggs / Android Authority
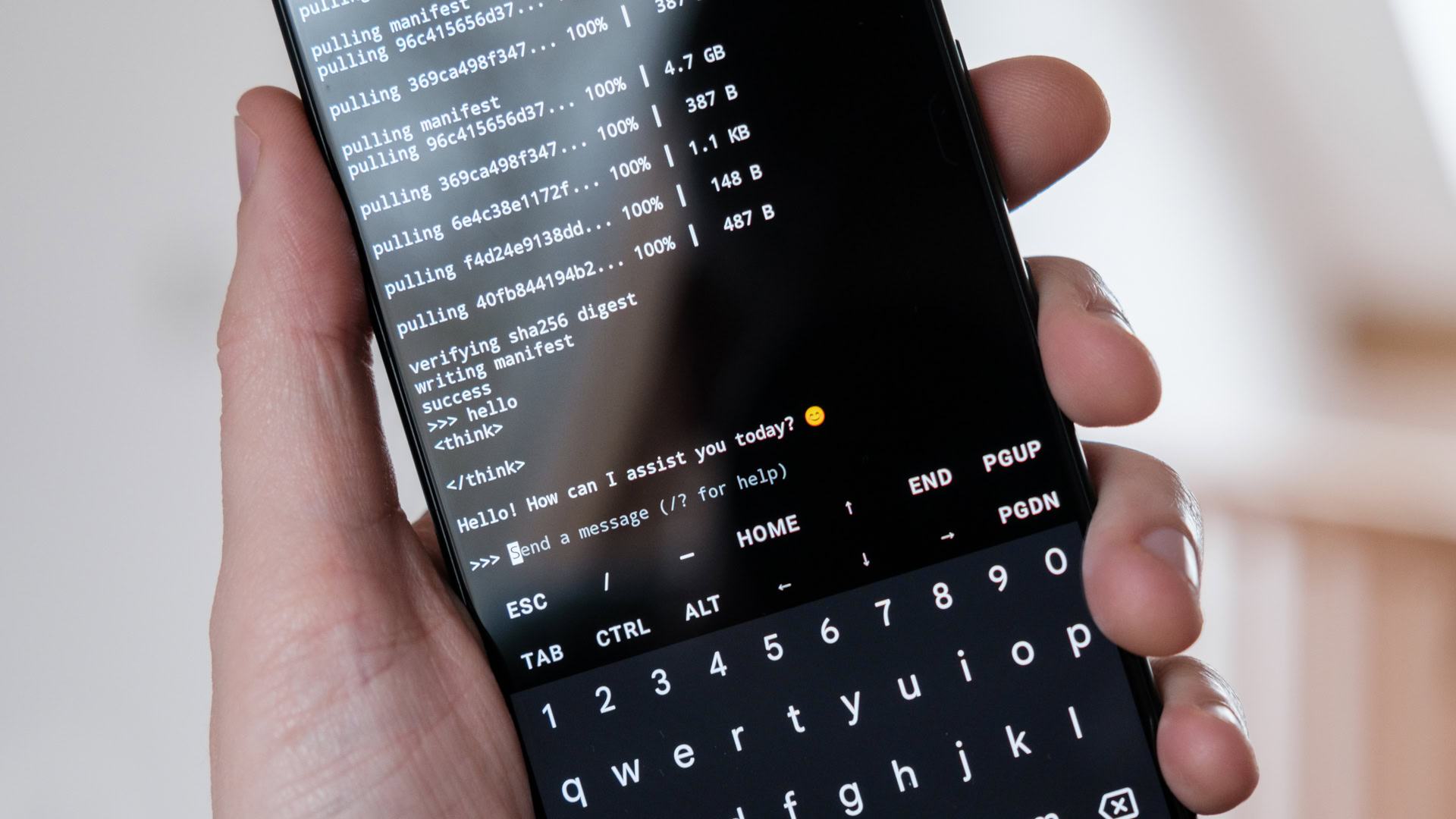
Cette deuxième méthode implique des querelles de ligne de commande via Termux pour installer Olllama, un outil populaire pour exécuter les modèles LLM localement (et la base de PocketPal AI) que j’ai trouvé un peu plus fiable que l’application précédente. Il existe quelques façons d’installer Olllama sur votre téléphone Android. Je vais utiliser ça plutôt intelligent Méthode de Davide Fornelliqui utilise Properme pour fournir un environnement Debian frais (et facilement amovible) avec lequel travailler. C’est le plus facile à installer et à gérer, d’autant plus que vous finirez probablement par retirer Olllama après avoir joué un peu. Les performances avec Proot ne sont pas tout à fait natives, mais c’est assez bon. Je suggère de lire le guide complet pour comprendre le processus, mais j’ai énuméré les étapes essentielles ci-dessous.
Suivez ces étapes sur votre téléphone Android pour installer Olllama.
- Installer et ouvrir le Application Termux
pkgupdate && pkg upgrade– passer aux derniers packagespkg install proot-distro– Installer Proot-Distropd install debian– Installer Debianpd login debian– Connectez-vous dans notre environnement Debiancurl -fsSL |sh– Télécharger et installer Olllamaollama serve– Commencez à exécuter le serveur Olllama
Vous pouvez quitter l’environnement Debian via CTRL+D à tout moment. Pour supprimer Olllama, tous vos modèles téléchargés et l’environnement Debian, suivez les étapes ci-dessous. Cela ramènera votre téléphone à son état d’origine.
CTRL+Cet / ouCTRL+D– Quittez Olllama et assurez-vous que vous êtes déconnecté de l’environnement Debian à Termux.pd remove debian– Cela supprimera tout ce que vous avez fait dans l’environnement (cela ne touchera rien d’autre).pkg remove proot-distro– C’est facultatif, mais je supprimerai également ProoT (ce n’est que de quelques Mo, vous pouvez donc le garder facilement).
Avec Olllama installé, connectez-vous à notre environnement Debian via Termux et exécutez Olllama Serve Pour démarrer le serveur. Vous pouvez appuyer CTRL+C Pour mettre fin à l’instance du serveur et libérer les ressources de votre téléphone. Pendant que cela fonctionne, nous avons quelques options pour interagir avec Olllama et commencer à exécuter des modèles de langues importants.
Vous pouvez ouvrir une deuxième fenêtre dans Termux, vous connecter à notre environnement Debian et procéder avec Interactions de ligne de commande Olllama. C’est le moyen le plus rapide et le plus stable d’interagir avec Olllama, en particulier sur les smartphones à faible Ram, et est (actuellement) le seul moyen de supprimer les modèles pour libérer le stockage.
Pour commencer à discuter avec Deepseek-R1, entrez ollama run deepseek-r1:7b. Une fois qu’il est téléchargé, vous pouvez taper dans la ligne de commande et le modèle retournera des réponses. Vous pouvez également choisir tout autre modèle de taille appropriée dans le bien organisé Bibliothèque ollla.
ollama run MODEL_NAME– Télécharger et / ou exécuter un modèleollama stop MODEL_NAME– Arrêtez un modèle (Olllama décharge automatiquement les modèles après cinq minutes)ollama pull MODEL_NAME– Télécharger un modèleollama rm MODEL_NAME– Supprimer un modèleollama ps– Afficher le modèle actuellement chargéollama list– Énumérez tous les modèles installés
L’alternative est d’installer Jhubi1 Application Olllama pour Android. Il communique avec Olllama et fournit une plus belle interface utilisateur pour discuter et installer des modèles de votre choix. L’inconvénient est que c’est une autre application à exécuter, qui mange une RAM précieuse et peut faire basculer un smartphone moins performant en rampe. Les réponses se sentent également un peu plus lentes que de fonctionner dans la ligne de commande, en raison des frais généraux de communication avec Olllama. Pourtant, c’est une mise à niveau solide de la qualité de vie si vous prévoyez d’exécuter perpétuellement un LLM local.
Quels LLM puis-je exécuter sur un smartphone?
Robert Triggs / Android Authority
Tout en regardant le processus de réflexion de Deepseek est impressionnant, je ne pense pas que ce soit nécessairement le modèle de grande langue le plus utile, en particulier pour fonctionner sur un téléphone. Même le modèle de paramètres de sept milliards s’arrêtera avec des conversations plus longues sur une 8 élite, ce qui en fait une corvée à utiliser lorsqu’il est associé à sa longue chaîne de raisonnement. Heureusement, il y a des charges plus de modèles à choisir qui peuvent fonctionner plus rapidement et fournir des résultats d’excellents résultats. Meta’s Lama, Microsoft’s Phi et Mistral peuvent tous fonctionner bien sur une variété de téléphones; Il vous suffit de choisir le modèle de taille le plus approprié en fonction de la RAM et des capacités de traitement de votre smartphone.
D’une manière générale, trois milliards de modèles de paramètres auront besoin jusqu’à 2,5 Go de RAM libre, tandis que sept et huit milliards de modèles de paramètres ont besoin d’environ 5 à 7 Go pour les maintenir. Les modèles 14B peuvent manger jusqu’à 10 Go, etc., doublant à peu près la quantité de RAM à chaque fois que vous doublez la taille du modèle. Étant donné que les smartphones doivent également partager la RAM avec le système d’exploitation, d’autres applications et GPU, vous avez besoin d’au moins un tampon à 50% (encore plus si vous souhaitez maintenir le modèle en cours pour déplacer le modèle dans l’espace d’échange. En tant que stade brut, les téléphones avec 12 Go de RAM rapide exécuteront sept et huit milliards de modèles de paramètres, mais vous aurez besoin de 16 Go ou plus pour tenter 14B. Et rappelez-vous, les partitions Pixel 9 Pro de Google sur un peu de RAM pour son propre modèle Gemini.
Les téléphones Android peuvent choisir parmi une vaste gamme de modèles d’IA plus petits.
Bien sûr, davantage de paramètres nécessitent également une puissance de traitement considérablement plus importante pour regrouper le modèle. Même l’élite Snapdragon 8 ralentit un peu avec PHI-4: 14B de Microsoft et Qwen2.5: 14b d’Alibaba, bien que les deux soient raisonnablement utilisables sur le colossal 24 Go Asus Rog Phone 9 Pro que j’ai l’habitude de tester. Si vous voulez quelque chose qui fonctionne à la lecture du rythme sur le matériel actuel ou de dernière génération qui offre toujours un niveau de précision décent, restez avec 8b au maximum. Pour les téléphones plus anciens ou de milieu de gamme, la chute avec des modèles 3B plus petits sacrifiez beaucoup plus de précision, mais devrait permettre une sortie de jeton qui n’est pas un rythme d’escargot complet.
Bien sûr, c’est juste si vous voulez exécuter l’IA localement. Si vous êtes satisfait des compromis du cloud computing, vous pouvez accéder à des modèles beaucoup plus puissants comme Chatgpt, Gemini et la profondeur pleine grandeur via votre navigateur Web ou leurs applications dédiées respectives. Pourtant, la gestion de l’IA sur mon téléphone a certainement été une expérience intéressante, et de meilleurs développeurs que moi pourraient exploiter beaucoup plus de potentiel avec les crochets API d’Olllama.